백엔드 개발 중 해야할 작업을 나중으로 미루는 것은 성능 및 서비스 안전성에 긍정적인 효과를 줄 때가 많다. 마이크로서비스 패턴(MSA)의 구조 역시 이러한 철학을 바탕으로 되어있고, 메시징 큐(MQ)를 통한 비동기 구조로 채택하는 경우가 많다.
하지만 아주 작은 작업을 위해 별도의 서버와 프로젝트를 구성하지 못하는 경우도 있다. 그래서 기능 중 일부를 위와 같은 기능으로 비동기화하여 그 기능을 동일 서버에서 처리하도록 하는 경우가 있다. 그리고 이런 기능은 아마 당장은, 혹은 그냥저냥 잘 굴러갈 수 있다.
잘 굴러가는데 왜 뻘글을 쓰고있냐면, 이게 장기적으로 매우 나쁜 선택지가 됐기 때문이다.
발단은 서버의 성능 확인을 위한 부하 테스트 작업이었다.
비동기로 등록된 작업의 스레드 작업 우선순위는 당장 서버로 진입하는 request보다 후순위로 밀리는 것이 당연하다. 이는 실제 테스트를 통해 확인하였다. 하지만 결국 예약된 비동기 작업 또한 처리가 되어야 하고, 서버 OS의 스케쥴링 규칙과 작업의 지연 시간 증가로 작업 실행 우선 순위는 점점 상승하게 된다. 이 순위가 당장 처리되어야 할 진입 request의 우선순위보다 밀리게 될 때 문제가 발생했다.
0.00x~0.x 초 사이로 빠르게 처리되어야 할 reqeust의 작업이 대량의 비동기 작업들에 밀려 x초 단위로 지연이 발생한 것이다.
쉬벌
서버의 부하가 많을 때 발생하는 조건부 지연이지만, 백엔드 개발이란게 원래 부하 받을 때 안전하게 돌아가라고 하는 개발인데 이게 고려가 안된 것이다.
그리고 사실 이건 해결책을 내기도 힘든게 별도 비동기 처리용 서버를 당장 새로 만들 수도 없고, 그렇다고 이제와서 동기(synchronous) 처리를 하기에도 애매하다.
사진 5. controller war 파일 실행 및 프로세스 확인사진 6. Controller 화면이 나오는 것을 확인!
기본 계정은
아이디 : admin
비밀번호 : admin
이다
그리고 이하 설명은 한국어 베이스로 진행할 것이기 때문에 언어는 한국어로 설정할 것이다.
사진 7. 정상적으로 진행 됐다면, 이렇게 나온다. 아무코토 없다.
5-2. nGrinder-Agent
Controller가 준비됐으니, 부하 발생기인 Agent를 준비해보자.
Agent의 실행 파일은 Controller를 실행시키면 얻을 수 있다.
사진 8. 우측 상단 계정을 (여기선 admin) 누르면, 여러 기능을 볼 수 있다.
사진 8을 따라 우측 상단의 계정을 클릭하면, 플로팅 메뉴가 나오는 것을 알 수 있다.
해당 메뉴에서 "에이전트 다운로드"를 클릭하면, ngrinder-agent-(Controller의 IP).tar 압축 파일이 다운로드 되는 것을 알 수 있다.
* 해당 압축 파일은 실행 가능한 자바 프로젝트의 압축 파일이기 때문에, 사용할 위치에서 압축만 풀어주면 된다.
사진 9. Agent 파일을 원하는 위치에 놓고 압축을 풀어준다.사진 10. 압축을 푼 후 보면 ngrinder-agent 폴더가 형성된 것을 확인할 수 있다. 사진 11. 10번 사진에서 생성된 폴더에 들어가보면, 실행 파일이 들어가있는 lib 폴더와 리눅스/윈도우 용 스크립트 파일, 그리고 초기 설정용 __agent.conf파일이 있다.
사진 10과 11을 보면 압축을 풀었을 때 nGrinder-agent 폴더가 생성된 것과 폴더 하위 경로에 실행 스크립트/실행 파일/__agent.conf 파일이 있는 것을 확인할 수 있다.
여기서 먼저 해야할 것은 __agent.conf 파일의 수정이다.
사진 12. __agent.conf 파일 내부 내용
하단에 주석이 되어있는 것은 사용하지 않는다. (추가적인 기능이 있는 것이겠지만, 기본적으로 사용하지 않았다. 자료도 적고 테스트 진행에 있어서 필요하지 않았다.)
필요한 것은 상단의 agent.controller_host 이다.
현재 작성하고 있는 예시는 시험용 예시이기 때문에 Controller와 Agent가 하나의 기기(노트북)에서 함께 실행하지만,
본래의 목적 달성을 위해서는 Controller와 Agent는 다른 서버 머신에 있어야 한다. 이 때 실행되는 Agent가 Controller를 바라보게 되는데 그것을 위해 Controller_host, 즉 Controller의 IP와 Controller_port를 필요로 하게 된다.
* Controller가 설정 수정 없이 디폴트로 수정되었다면, Web 접근용 포트 이외에 Agent 접근용 16001 포트와 부하 테스트 사용을 위한 12000~12009 포트가 함께 개방된다.
지금 예시에서는 localhost로 실행되기 때문에 그냥 실행하겠다.
실행 방법은 윈도우의 경우 run_agent.bat 혹은 run_agent_bg.bat을 실행하고, 리눅스의 경우 run_agent.sh 혹은 run_agent_bg.sh를 실행하면 된다. (_bg는 백그라운드로 실행하겠다는 의미이다. 실제 동작 확인을 하고 싶다면 run_agent를, 아니면 run_agent_bg를 실행시키면 된다.)
사진 13. nGrinder-agent의 실행 및 프로세스 확인
예시에서는 _bg파일로 스크립트를 실행하였고, Agent 자바 프로세스가 정상적으로 실행된 것을 확인할 수 있다.
그럼 Controller에서 정상적으로 인식했는지 확인해보자
사진 14. 우측 상단 계정을 클릭 후 에이전트 관리
우측 상단 계정 클릭 후, 에이전트 관리로 들어가보자
사진 15. Agent가 등록되어 있는 것을 확인
Agent의 정보가 등록된 것을 확인할 수 있다.
주의) 내 경우 실무 적용 시 aws subnet 환경에서 해당 작업을 진행했는데, Controller의 외부 접근용 IP를 __agent.conf에 설정 후 실행 시 Connection refused 에러가 발생했었다. 정확한 이유는 모르겠지만 내부 IP로 재설정 후 실행했더니 해결되었다.
여기까지만 해도 부하 테스트를 충분히 진행할 수 있기 때문에 보통 여기서 설명이 끊긴 경우가 대부분이었다.
하지만 어림도 없지. 팀장님께선 리소스의 모니터링도 볼 수 있어야 한다고 하셨다.
팀장님은 모니터가 좋다고 하셨어
5-3. nGrinder-Monitor
마지막 Monitor를 보자.
Monitor는 nGrinder-architecture 구성 중에서 target server, 부하를 받을 서버에 설치되어야 한다.
Agent에 의해 부하를 받는 동안에 부하 대상의 CPU, Memory, Network receive/send Queue를 시각화하여 함께 볼 수 있기 때문에 적용하여 손해보는 것은 단 하나도 없다.
하지만 개인적으로 처음 설정할 때 가장 고통 받았던 것이 Monitor다.
설정 이전에 이해를 돕기 위한 설명!
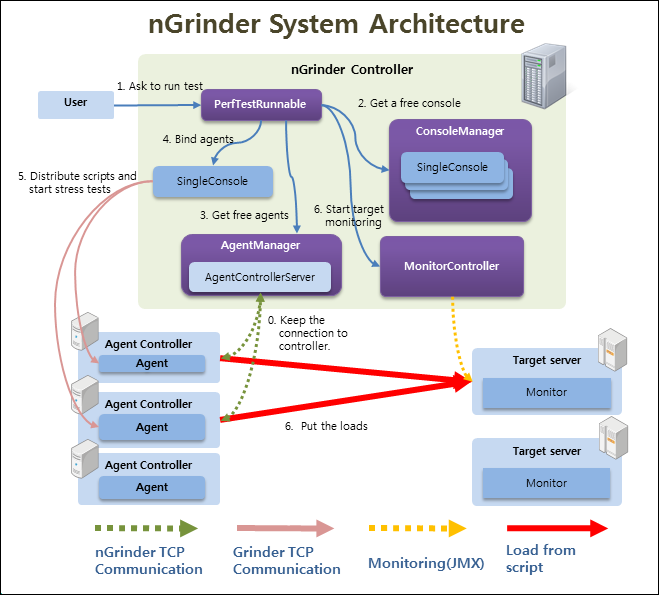
Agent는 Agent가 Controller를 보는 것이다. 그렇기에 Agent에 Controller를 등록했다.
그렇다면 Monitor는 어떨까? 사진 1의 nGrinder architecture를 보면 알 수 있듯이, Controller가 Monitor를 본다고 되어있다.
그럼 이제 Monitor 설치를 해보자
사진 15. 사진 14와 똑같은 사진이다.
* 사진은 위에 올려보기 싫으니까 똑같은거 다시 올렸다.
플로팅 메뉴에서 모니터 다운로드를 확인할 수 있다. 다운받자.
사진 16. Agent와 동일하게, 압축 파일을 받았다
이후 Agent와 동일하게 tar -xvf 명령어로 압축을 풀어서 생성되는 ngrinder-monitor 폴더로 들어가보자.
사진 17. Agent를 잘못 들어온 것이 아니다. Monitor 맞다
Agent와 거의 비슷해보이고 __agent.conf 파일이 있어 잘못들어왔나 싶겠지만, Monitor경로로 제대로 들어온 것이 맞다!
사진 18. Monitor의 __agent.conf 내용
수정하지 않은 __agent.conf의 내용이다.
실행 모드는 monitor로 되어있는데, 이것은 Monitor가 원래 Agent와 동일한 프로젝트였던 것으로 추측한다.
* 증거 없이 이렇게 추측하는 이유는, 구버전의 설정을 설명한 다른 글들에서 볼 때 Monitor의 __agent.conf 포맷이 사진 18과는 다르게 Agent의 그것과 포맷이 동일하기 때문이다. 뻘소리니 그냥 Monitor설정이구나 하고 넘어가자
그 아래 주석 처리 되어있는 monitor.binding_ip는 리소스 모니터링을 할 대상 서버 머신의 IP이다. 주석처리가 되어있다면 디폴트로 Monitor가 실행되고 있는 서버 머신의 리소스를 보게된다.
monitor.binding_port는 monitor가 실행될 때 개방하는, nGrinder-Controller가 nGrinder-Monitor로 접근하기 위한 port이다. nGrinder-Controller의 기본 설정으로 지정되어있기 때문에 수정은 하지 않겠다.
그럼 실행을 해보자
사진 19. Controller, Agent, Monitor 모두 실행 중인 것을 확인
여기까지 했으면 거의 다 된 것이다.
마지막으로 남은 Controller에 Monitor를 등록하는 과정을 진행해보자.
사진 20. Controller 성능 테스트 페이지
Controller 상단의 "성능 테스트" 탭을 클릭하면, 위와 같은 페이지에 진입하게 된다.
우측에 있는 "테스트 생성" 파랑색 버튼을 눌러보자
사진 21. 테스트 설정 페이지
위와 같은 테스트 설정 페이지가 나오는데, 우리는 여기서 테스트를 하는 방법은 보지 않을 것이다.
사실 작성은 하고 싶은데, 부하 테스트에 사용할 서버를 올려놓은게 없다.
여기서 봐야하는 것은 왼쪽 아래에 "테스트 대상 서버"라고 쓰여진 텍스트 박스이다. 텍스트 박스 오른쪽 아래 "+ 추가"를 눌러보면 도메인과 IP를 추가할 수 있는데, IP만 추가해주면 설정이 끝나게 된다.
여기까지 설정한 후 테스트를 진행하면, 상세 보고서에서 좌측 하단에 타겟 서버 당 시각화된 리소스 모니터 데이터를 확인할 수 있다.
AWS에서 권장하는 데이터를 AZ(Availability Zone) 여러 곳에 분산하여 저장하는 정책이다. ex) AWS에서 제공하는 Cache 서버를 구성하는데 단일 클러스터로 구성하였다. 이런 상황에서 AWS 오류로 Cache 서버가 죽어서 서비스에 차질이 생길 수 있으니, 서울-Region-a와 서울-Region-b 두 곳에 분산시켜 Fail Over 대책을 세워야 한다는 것이다
서비스 안정성을 위해서 HA를 위해 Multi-AZ를 시키는 것은 맞지만 이 정책에는 일단 함정이 있다. AWS의 서비스 안정성은 99.99%(서비스 별로 다름)로 AWS측에서 일부 서비스를 재시작하거나 내부 오류가 발생하여 서비스 기능이 일시 중지 될 수 있다. 해당 내용은 공식 매뉴얼에 기재된 것으로 실제 발생할 수 있는 상황이다. 이 때 AWS 오류로 인해 일부 기능이 작동을 하지 않는 경우, Multi-AZ를 적용하지 않아 피해를 본 고객사에게는 피해 보상을 하지 않는다. (물론 Multi-AZ-AZ는 추가적인 인스턴스 혹은 AWS EBS를 대여하는 것이므로 비용이 늘어난다.)
AWS가 죽어봤자 얼마나 죽겠어! 라고 생각할 수 있지만 의외로 잘 죽는다. 2019년 AWS 도쿄 리전의 일부 AV에 속한 캐싱 서버가 오류를 일으켜, 해당 Region과 AZ에 단일 캐싱을 두고 있던 기업들이 피해를 본 적이 있다. (내 기억으론 그 때 넥슨 일부 게임들도 오류가 났었던 꽤 큰 이슈로 알고있다.)